A paper accepted for LREC-COLING 2024! ✌✌
The European Language Resources Association (ELRA) and the International Council for Computational Linguistics (ICCL) are co-hosting the Joint International Conference on Computational Linguistics, Language Resources and Evaluation 2024 (LREC-COLING 2024), which will take place from 20-25 May 2024 in Turin, Italy.
The joint conference will focus on researchers and practitioners in the fields of computational linguistics, speech processing, multimodality and natural language processing, with an emphasis on evaluation and resource development to support work in these areas. Continuing the long tradition of COLING and LREC, this joint conference will highlight major challenges, offer oral presentations and extensive poster presentations, and provide ample opportunities for participants to network, with a rich social programme.
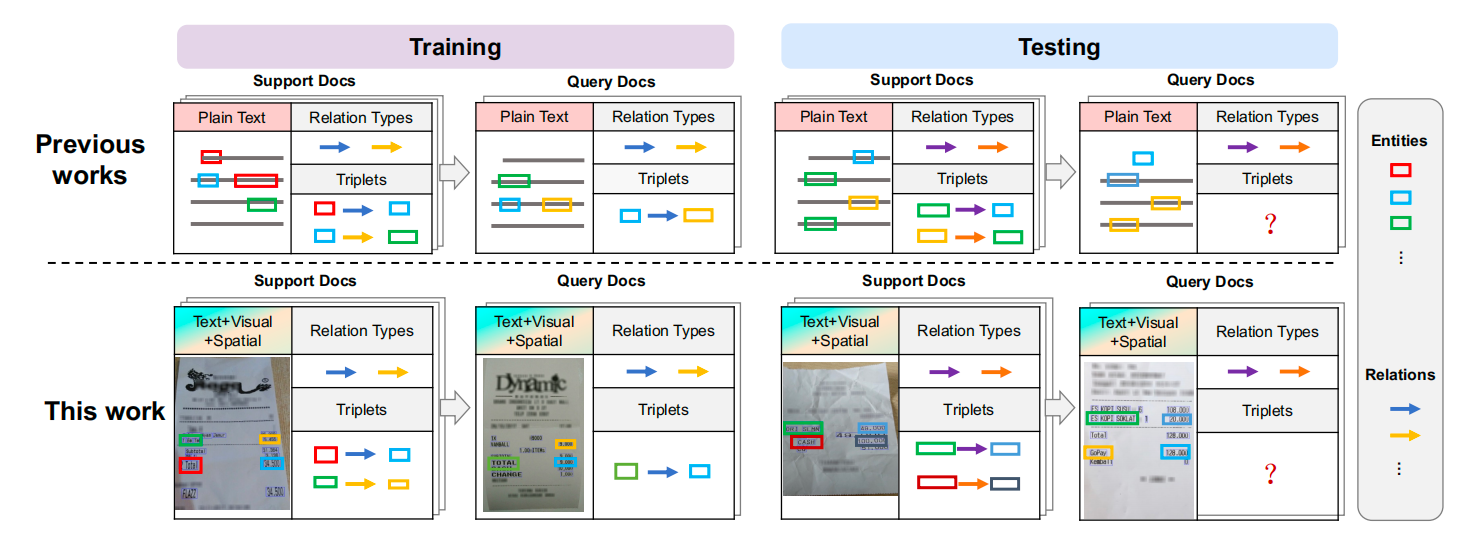
This time, one paper of the work of the Natural Language Processing and Human-Computer Interaction Laboratory (H!NTLAB) of Shanghai University, in which Tang Li was mainly involved, was accepted by LREC-COLING 2024. The brief introduction of the accepted paper is as follows: Towards Human-Like Machine Comprehension. Few-Shot Relational Learning in Visually-Rich Documents
Type: Long Paper
Author(s): Hao Wang (Lecturer), Tang Li (M.S. Candidate, Class of 2021), et al.
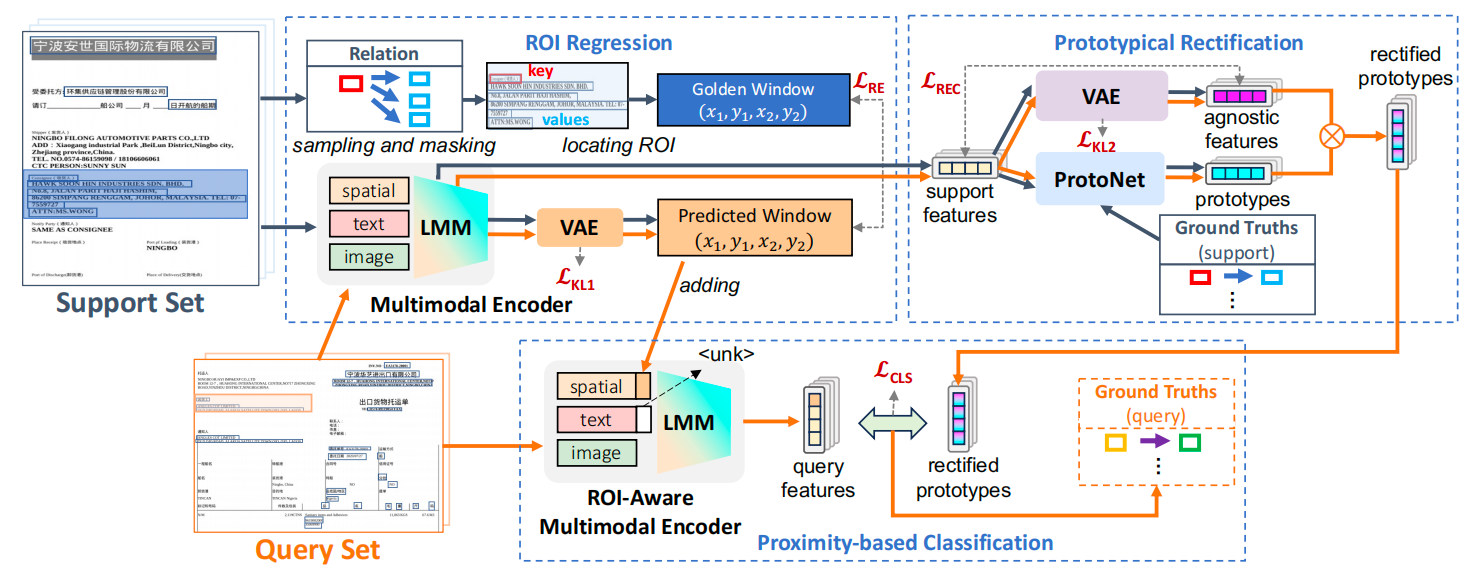
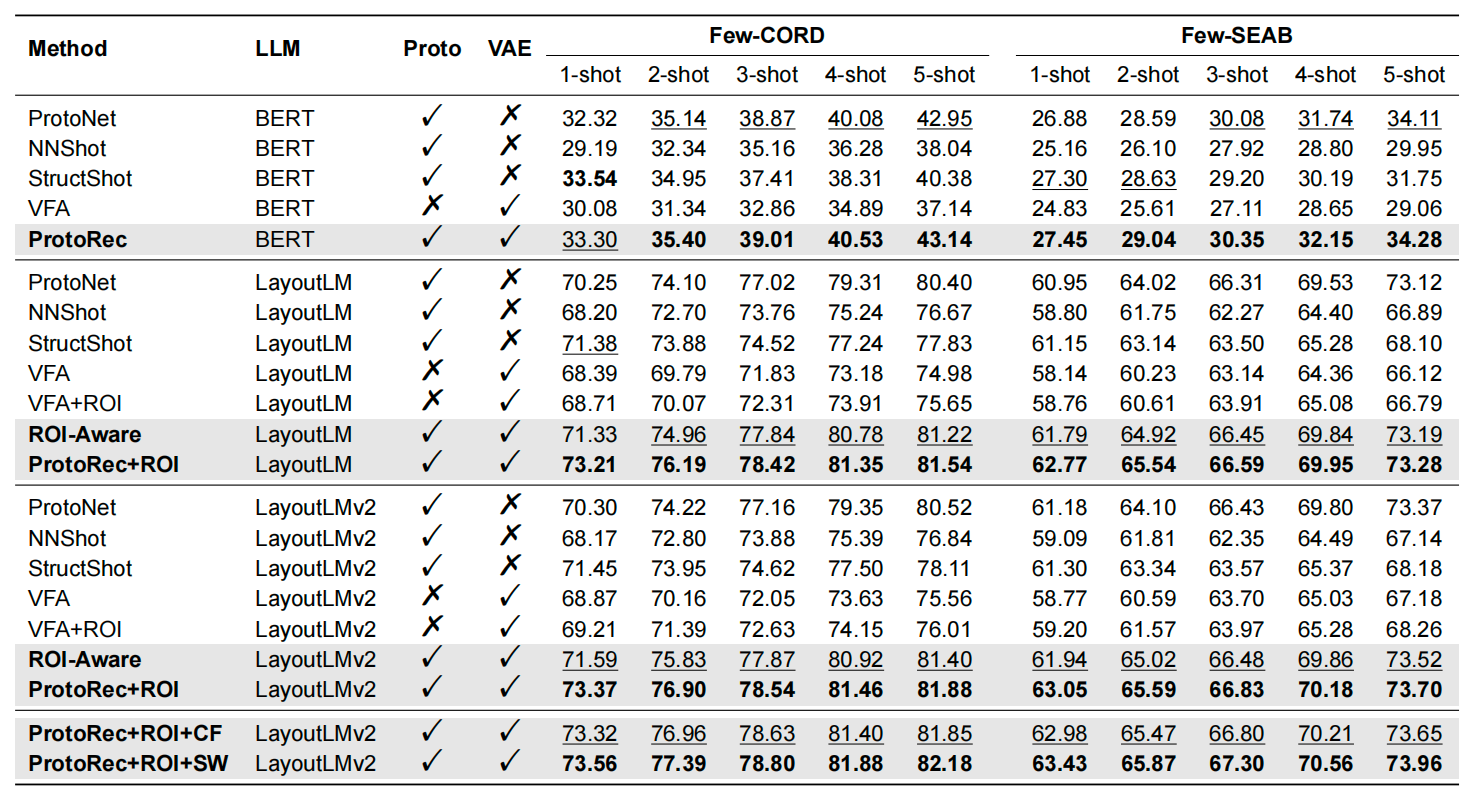
Introduction: Key-value relationships are common in visually-rich documents (VRDs), which are usually described in different spatial regions accompanied by specific colours and font styles. These non-texts are important features that greatly enhance human understanding of this relational triad. However, current document AI approaches are unable to take into account this valuable a priori information related to visual and spatial features, resulting in sub-optimal performance, especially when dealing with a limited number of examples. To address this limitation, our research focuses on few-shot relational learning, especially for the extraction of key-value relation triples in VRD. In view of the lack of datasets suitable for this task, we have introduced two new few-shot datums based on the existing supervised datum datasets. In addition, we propose a variational method that combines relational two-dimensional space prior and prototype correction techniques. This approach aims to generate relational representations that are aware of spatial context and unseen relationships in a manner similar to human perception. Experimental results demonstrate the effectiveness of our proposed method and demonstrate its ability to outperform existing methods. This research also opens up new possibilities for practical applications.